Reward Distribution
Here we describe and develop a heuristic model for attributing credit and rewards in the context of a DAO's evdience-based governance processes.
Relation to Computer Aided Governance
Computer Aided Governance is increasingly being put into practice as "a decision-support process that leverages blockchain technology and cadCAD to simulate the potential results of governance policies, leading to better informed decision making". In the particular Evidence-Based decision process described herein, we extend or generalize this focus on integrative simulation models to include the types of evidence in the following section.
Types of evidence
In general, the types of evidence considered in DAO governance is, in order of increasing effort & utility to decision makers:
Raw Data
Graphs / Plotting / Visualization
Clustering (Unsupervised)
Machine Learned (or Statistical) modeling (Predictive – Supervised)
Integrative Simulation Models (including cadCAD)
Reports / Analyses
Evidence-Based Decision Making Process
Consider a potential DAO's evidence-based decision-support cycle in Figure 1, below;
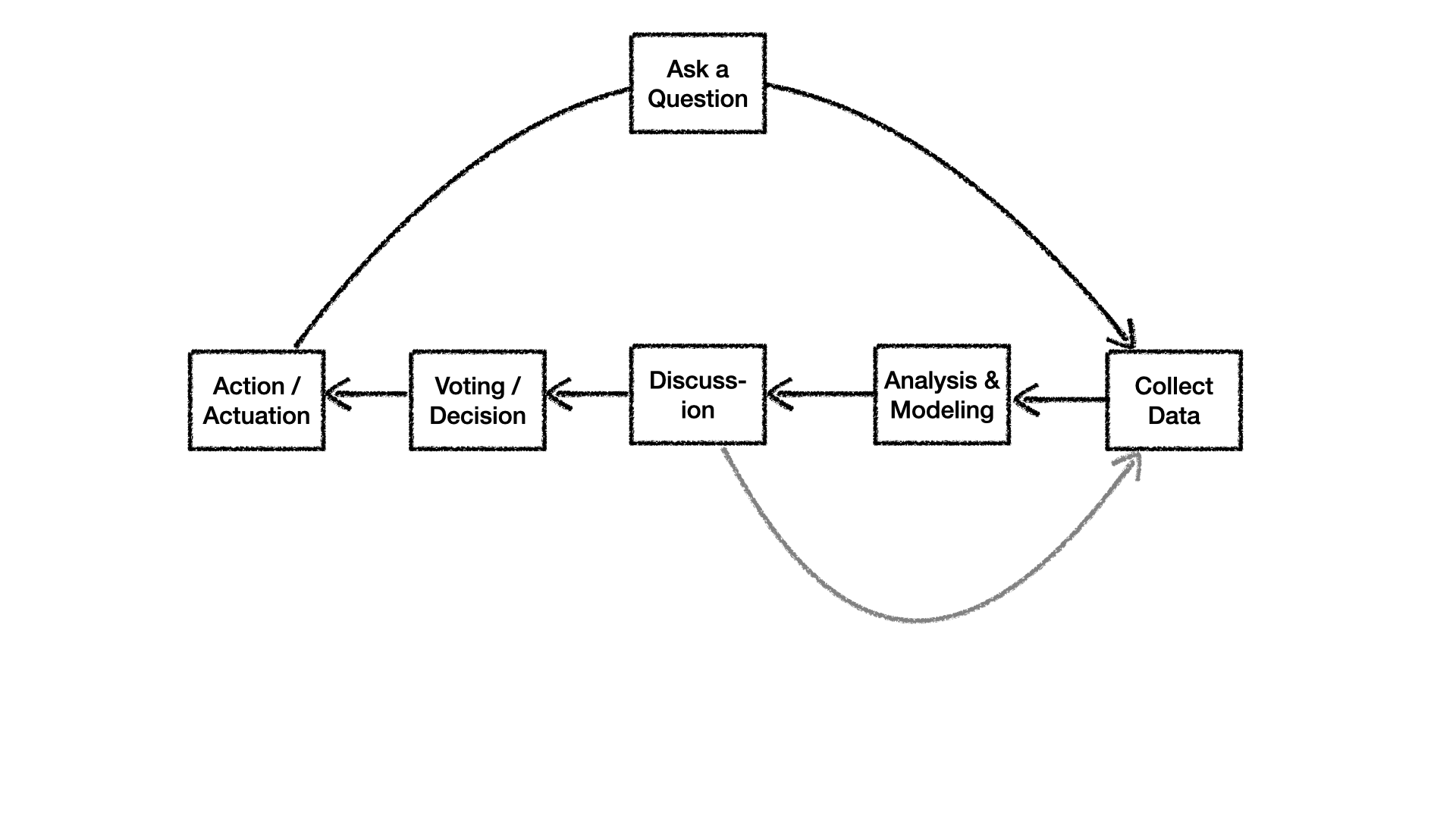
Figure 1. An evidence-based decision support cycle executed by a DAO.
Initially, a question to be decided is put in front of governance, for example whether or not to incubate a potential candidate project, on the appropriate subDAO forum. Then, data is collected, analyzed (often using models), and thoroughly discussed. Following discussion, it may become clear that more evidence is required before making a decision, in which case there's a mini-feedback-loop that takes the process back to the data collection phase, since additional supporting evidence is required. Or perhaps there is consensus in the community that there is enough evidence (this can be done through informal polling or other signaling), then the decision proceeds to a binding vote. Once the action is taken on the decision, the new activity will generate new information, that can be considered in future decisions. This is clearly a simplification because in practice, data is never perfectly clean, and Data Collection involves sourcing and cleaning data, and often transforming the format to something more amenable to the analysis step. Additionally, several of these decision processes may be occurring simultaneously concerning different issues before the DAO.
Also, more automated models and applications of this process are possible. By removing the human-centric "ask a question" and "discussion" phases, and automating the Voting/Decision phase (through various means including AI) the loop starts looking more like the classical closed-loop control system.
A Case Study
Soon after launching the Open DeFi DAO will feature a governance discussion forum, with a section dedicated to producing evidence for decision support populated by a self-organised data-oriented community of contributors.
Let's say, for example, a sub-topic of the forum is related to providing evidence to support the decision whether or not to incubate a new project involving a new innovative type of meta-vault.
Let's say the forum topic related to this meta-vault decision contains several posts.
Two high-level reports are there, built on earlier, foundational analyses. The posted "Token Economics Report" presents results from & discusses earlier analyses and models posted on the forum. It adds value by bringing together and presenting the previous results comprehensively.
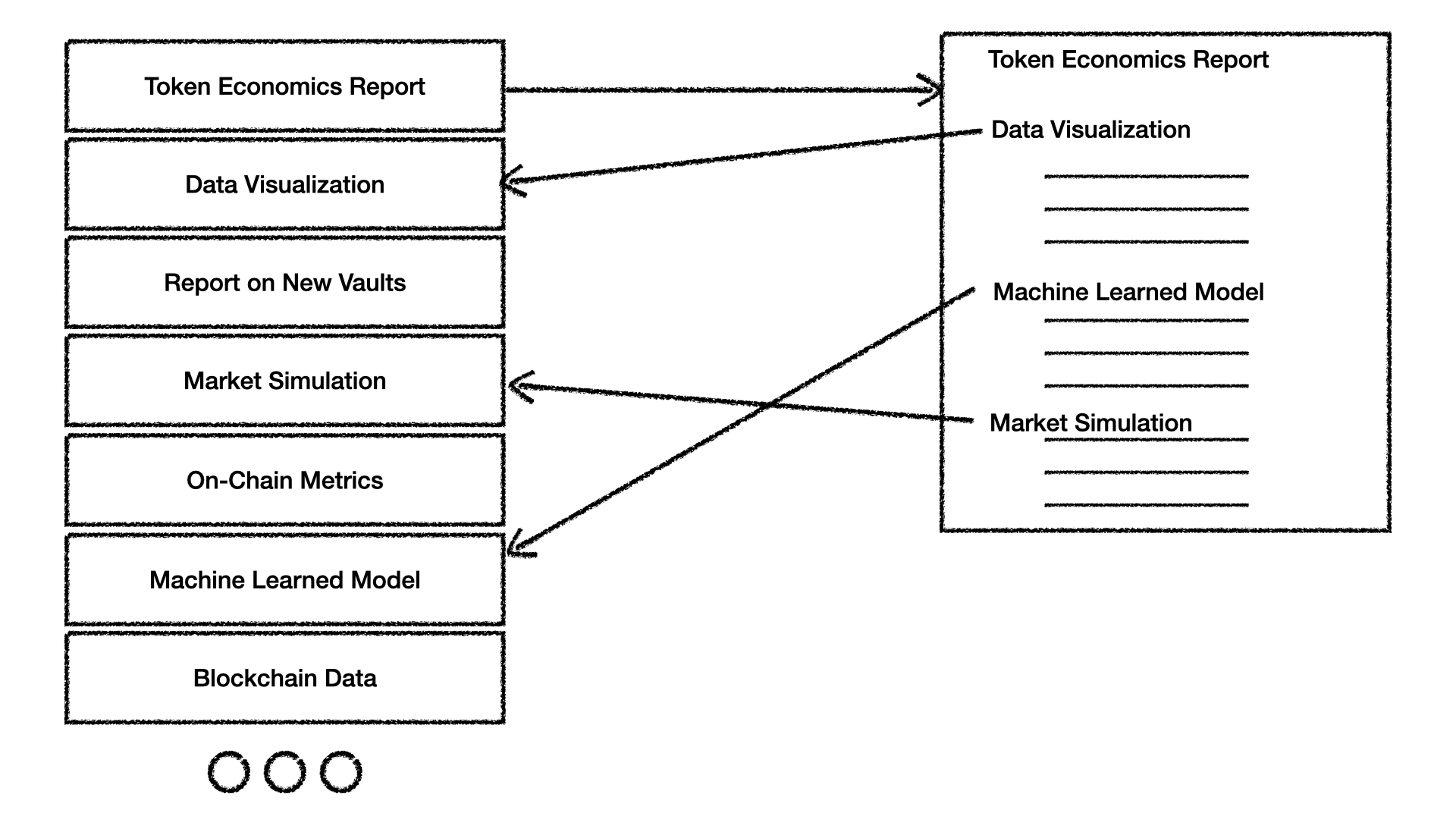
Figure 2. A selection of forum post titles is shown, with the "Token Economics Report" showing which previous posts it refers to and builds upon. The links are understood to be cryptographic hashes.
The "Report on New Vaults" is another top-level report that summarizes other evidence, although its constituent parts are not shown, to simplify the discussion.
In the spirit of Radical Transparency the norms of the community require reports and analyses to reference source material whether the source is raw data or some other artifact resulting from earlier analysis. Cryptographic hashes are used when referring to earlier evidence, providing a chain of provenance back to the original sources.
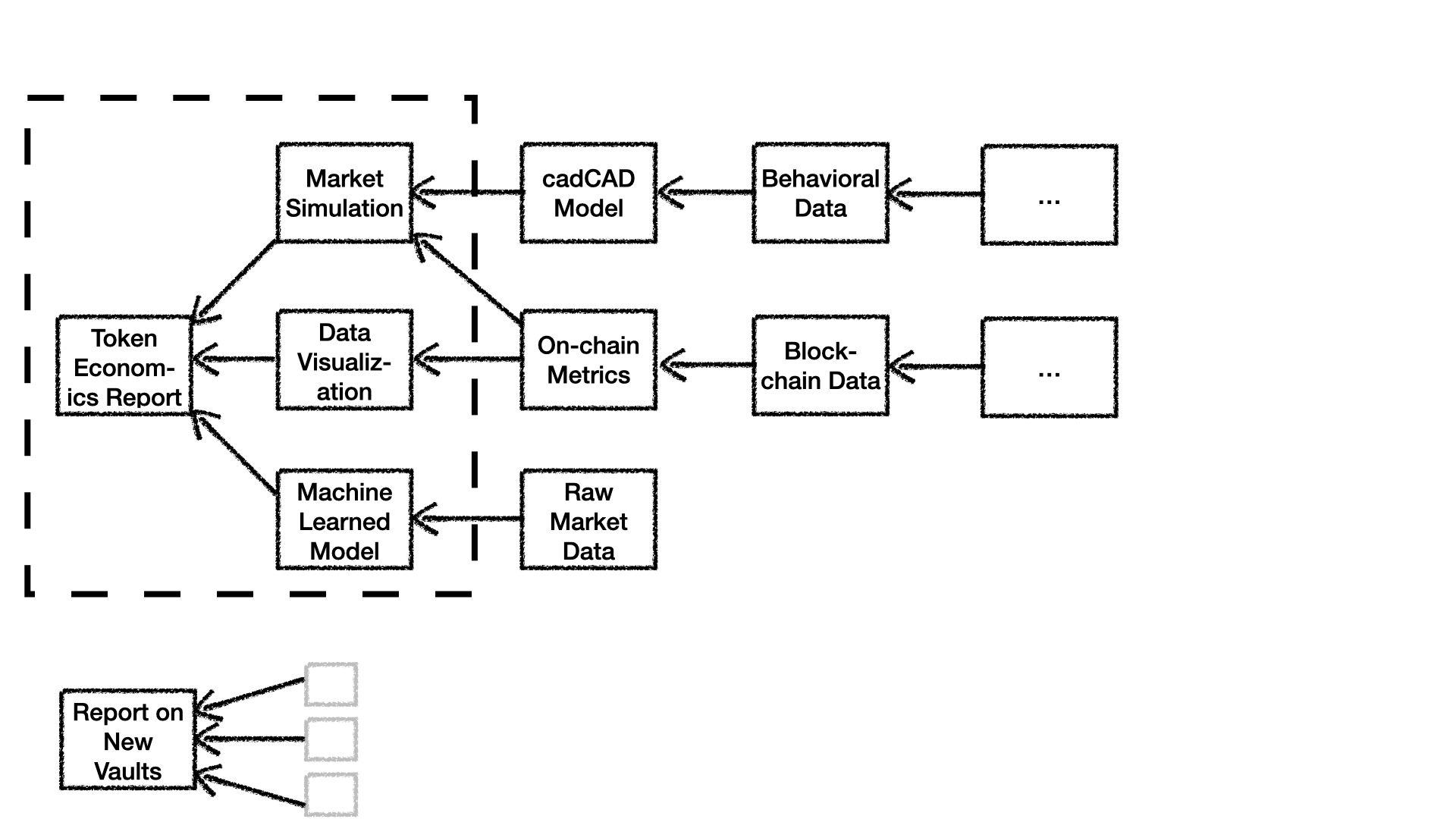
Figure 3. The provenance of sources underlying the decision support evidence on the forum.
The Figure 3 shows the provenance of data and analytics that are the foundation for the "Token Economics Report". It shows that the evidence from the "Machine Learned Model", "Data Visualization", and "Market Simulation", in turn, are based on evidence posted earlier to the forum including "Raw Market Data", "Blockchain Data", and "Behavioral Data". The "Report on New Vaults" is also based on earlier analyses, models, and data, but these are not shown for simplicity here.
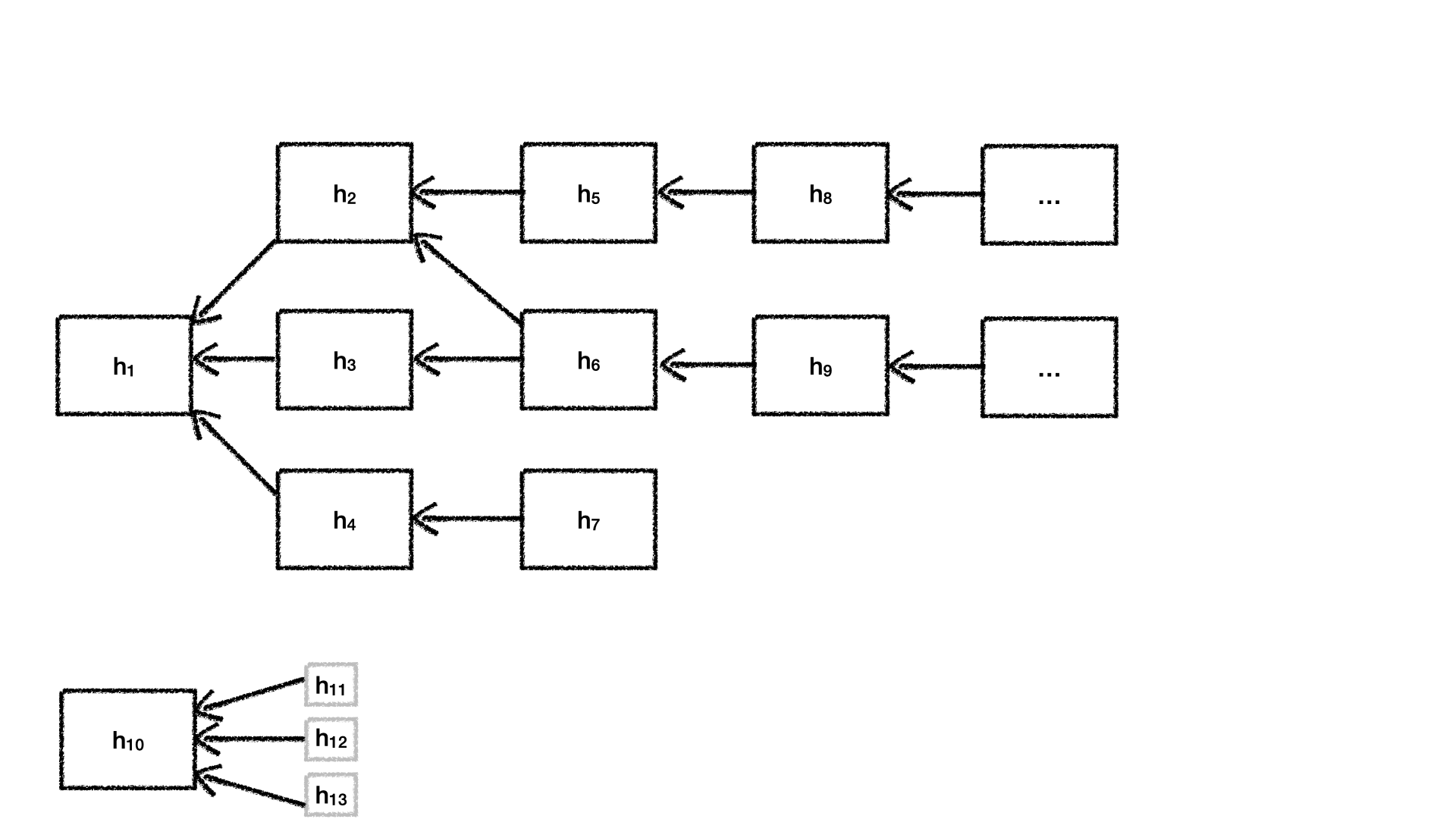
Figure 4. Decision support evidence as a Directed Acyclic Graph (DAG) of hashes.
We can form an Directed Acyclic Graph (DAG) Hout of the hashes of incubation decision support evidence on the forum which we will refer to as hi∈Hwhere H is the set of nodes in H. The directed edge between nodes hidenotes that the head points to the node referring to information in the node at the tail of the edge. In Figure 4, node h1incorporates information contained within nodes h1, h2and h3 .

Figure 5. Labeling the Sinks, Sources, Successor, and Predecessor nodes for a node h1 in an arbitrary DAG H
Let S+be the set of sinks that satisfy ∀hs∈S+:deg−(hs)=0
Furthermore, let S−be the set of sources that satisfy ∀hs∈S−:deg+(hs)=0
Then, for any H=∅,∣S+∣≥1and ∣S−∣≥1 that is, there is at least one source node and at least one sink node, for any non-empty set of evidence nodes H
Hmay or may not be a rooted graph.
Utility of Posted Evidence to the Decision Making Process
Let U(hi)denote a utility function that maps the evidence hito a utility ui.
In general, Ucould take many forms, and could be assigned by a subset of (or all) DAO participants, a process which could be modeled as a dynamic system of interacting Economic Agents.
Assume that the utility function has the property U(H)=∑i=0nU(hi)where n=∣H∣.
The Changing State of Available Evidence
The state or set of evidence in H evolves through the addition of new evidence hj to transition to a new state H+.
Initially the forum begins with no evidence H=∅.
And evidence is added over time,
H+=H∪hj:hj∈/H
hjcan be primary data, or source in the graph theory sense, that is, hj∈S−.
Alternatively, $h_j$ can be the result of a complex transformation Rj(Hj) where Hj⊆Htherefore, hj=Rj(Hj):Hj⊆Hwhere Rjis an arbitrary function, sequence of logical operations, or nonlinear algorithm including simulations and machine-learned transformations, or plain language argument.
Estimating Utility Contributions
We want to estimate ki, the utility contribution of each hi∈Hso that ultimately rewards can flow to the individual providers of hiproportional to their contribution.
Let Bibe the set of predecessor nodes to hi.
Let Jibe the set of successor nodes to hi.
Bottom-Up Perspective
The utility of the evidence node is the utility of the supporting evidence plus the "lift" or additional evidence generated by performing transformation Rj. Thus, we argue that: (1) U(hi)=U(Bi)+ki
Where kiis the value or Utility added by performing Ri(Bi). kican be thought of as the "credit" attributed to hiand by association the account that posted it.
We note that when U(hi)=U(Bi)this implies that ki=0 which corresponds to the case where evidence hireferences sources but does not deliver any additional useful insight over the predecessor evidence. We assume that such evidence won't have any successor evidence and the credit assigned directly by forum users, will tend towards 0.
If we assume that the contribution of hiis approximately proportional to the utility of its source evidence: ki≈U(Bi)then we can say, U(hi)=2∗kiand,
(2) ki=U(hi)/2
U(hi)is bounded as follows:
U(hj∈Ji)≥U(hi)≥U(Bi)
Top-Down Perspective
The total utility of evidence hifrom a "top down" perspective can be also expressed as,
(3) U(hi)=U(Ji∣hi)+U(Ci)
As before, let Jibe the set of successor nodes to hi, U(Ji∣hi)is the computed estimate of the utility of the contribution of hito the successor nodes, and U(Ci)is the estimated utility as assigned by forum members.
An expression to describe U(Ji∣hi)is then:
(4) U(Ji∣hi)=∑hj∈Jideg−(hj)α⋅U(hj)
Where αis an attenuation factor, which, in general adheres to 1≥α≥0and to be consistent with (2) can be α=1/2
Combined Perspective
Finally, by substituting (4) into (3):
U(hi)=∑hj∈Jideg−(hj)α⋅U(hj)+U(Ci)
and then substituting into (2) we get
ki=2∑hj∈Jideg−(hj)α⋅U(hj)+U(Ci)
Voting Member's Credit Allocation
Each voting member in the DAO receive a number of tokens κper governance decision the member voted in; these specialized tokens are only used to assign credit to evidence posted in the governance forum.
In the set of voting members P, each voting member p∈Passigns zero or more of their κtokens to signal the utility or importance of a particular piece of evidence hiThen, cpi is the credit that user passigns to hiand Ci=∑p∈Pcpiwith the constraint that ∑icpi≤κ
Assuming during some epoch the total awards available for distribution are A then the portion of Aallocated to hiis Ai=∑j∈Hkjki
The reward Ai gets sent to the address (user) who originally posted the evidence.
Interestingly, we have demonstrated that this credit assignment is possible without each voting member having to explicitly judge the utility of evidence against the predecessor or source evidence used.
Award Funding & Budget
The award budget A can be allocated using a mechanism called a Proposal Inverter which is useful for funding public goods. From the perspective of the DAO, evidence on the forum can be regarded as a public good. Periodically, one or more Sub-DAOs can vote to fund the Proposal Inverter's pool. This pool regularly drips funding according to a preset function, yielding the award budget Afor any particular epoch.
Spam Avoidance
The Proposal Inverter mechanism mentioned above, can also serve to disincentivise spam on the forum. We can require that Data Scientist contributors to the forum, need to stake a certain number of (governance) tokens per epoch in order to post evidence on the forum. This can be further augmented by using a bonding curve.
The staking mechanism itself incurs an opportunity cost on the posters - those expecting to waste the time of others will not get rewarded to compensate their staked tokens. This can be further augmented by allowing the community to slash the stake of posters that are spamming the forum.
Sybil Resistance
In general, decentralized governance is prone to so-called Sybil attacks whereby one member/voter pretends to be many individuals by partitioning tokens into several wallets or addresses. The DAO will periodically award Non-Fungible, Non-Transferrable, Contributor Tokens recognizing the contributions of individual contributors. These tokens act as a "proof of work" and thereby provide a form of soft Sybil resistance, because an attacker would have to put in a considerable amount of effort in order to make the requisite contributions across many different addresses.
Last updated
Was this helpful?